
Inductive Learning: Construct a classification rule in some predefined attribute language based on a training set of positive (+) and negative (-) instances.
Toy Example:Given the following inputs describing the stature,
hair color and eye color of 8 subjects, the ID3 algorithm will
generate the decision tree shown:
[1, short, blond, blue: +] [5, short, dark, blue: -] [2, tall, blond, brown: -] [6, tall, dark, blue: -] [3, tall, red, blue: +] [7, tall, blond, blue:+] [4, tall, dark, brown: -] [8, short, blond, brown: -]
The tree classifies the positive and negative examples into two categories: red heads or blue-eyed blonds (+) versus dark haired or brown-eyed blonds (-). Note that the height of these subjects is irrelevant.

| No. | Risk | History | Debt | Collateral | income |
|---|---|---|---|---|---|
| 1 | high | bad | high | none | $0-15K |
| 2 | high | unk | high | none | $15-35K |
| 3 | mod | unk | low | none | $15-35K |
| 4 | high | unk | low | none | $0-15K |
| 5 | low | unk | low | none | over $35K |
| 6 | low | unk | low | adequate | over $35K |
| 7 | high | bad | low | none | $0 to 15K |
| 8 | mod | bad | low | adequate | over $35K |
| 9 | low | good | low | none | over $35K |
| 10 | low | good | high | adequate | over $35K |
| 11 | high | good | high | none | $0 to $15K |
| 12 | mod | good | high | none | $15 to $35K |
| 13 | low | good | high | none | over $35K |
| 14 | high | bad | high | none | $15 to $35K |
function induce_decision_tree(Examples, Properties) {
if all entries in Examples are in the same class
return a leaf node labeled with that class
else if Properties is empty
return a leaf node labeled with disjunction of all classes in Examples
else {
select a property P and make it the root of the current tree
delete P from Properties
for each value, V, of P {
create a branch labeled V
let partition[V] be elements of Examples with values V for property P
call induce_decision_tree(partition[V], Properties) and attach result to V
}
}
}
As the in-class exercise reveals, if you choose a different propery as the base of the tree, you get a different tree.
Information Theory (Shannon, 1948) can be used to select the property that contributes the largest information gain as the root of each subtree.
Information Content: The amount of information in a message
is a function of the probability of the occurrence of each possible
message. Given a universe of messages M = {m1, m2, ...mn}
and a probability p(mi) for the occurence of each message,
the information content of a message in M is given by:
I(M) = Sum_from_1_to_n[-p(mi)log2(p(mi))]
Information content is measured in bits, but this is not the same notion of bit as in binary digit.
Coin Toss Example. The amount of information in a fair coin toss is
I(fair_coin) = -p(heads)log2(p(heads)) - p(tails)log2(p(tails))
= -1/2log2(1/2) - p(1/2)log2(1/2)) = 1 bit
Unfair Coin Toss. The amount of information for an unfair coin where
the coin has a 75% chance of being heads would be:
I(unfair_coin) = -3/4log2(3/4) - p(1/4)log2(1/4)) = 0.811 bits
Because knowledge would enable you to bet correctly 3/4 of the time, a message about the outcome of a given toss is worth less than a message about the outcome of a given toss of a fair coin.
Rule: At each level of the tree, choose the property that maximizes information gain.
We won't go into the details of computing information gain, other
than to say that for the root of the tree, the information gain for
property P is the difference between the total amount of information
in the tree and the expected gain of information for that property:
gain(P) = I(Credit_Risk_Table) - E(P)
The results for the Credit Risk Problem are:
| Property | Information Gain |
|---|---|
| Income | 0.967 bits |
| Credit History | 0.266 bits |
| Debt | 0.581 bits |
| Collateral | 0.756 bits |
Given these values, we would choose Income as the root property. And reapply this algorithm for each subsequent level. This leads to much smaller decision tree than our original tree for the Credit History Problem.
There were 23 Primitive attributes such as inability to move the king safely.
| Training Set Size | % of Universe | Errors in 10,000 Trials | Predicted Errors |
|---|---|---|---|
| 200 | 0.01 | 199 | 728 |
| 1,000 | 0.07 | 33 | 146 |
| 5,000 | 0.36 | 8 | 29 |
| 25,000 | 1.79 | 6 | 7 |
| 125,000 | 8.93 | 2 | 1 |
Quinlan's C4.5 (1996) is a refinement of ID3 that addresses some of these issues.
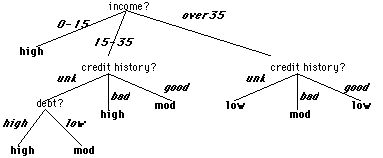{kind=link}